The transport and network layer protocols we have studied so far provide for the delivery of packets from a single source to a single destination. Protocols involving just one sender and one receiver are often referred to as unicast protocols.
A number of emerging network applications require the delivery of packets from one or more senders to a group of receivers. These applications include bulk data transfer (e.g., the transfer of a software upgrade from the software developer to users needing the upgrade), streaming continuous media (e.g., the transfer of the audio, video and text of a live lecture to a set of distributed lecture participants), shared data applications (e.g., a whiteboard or teleconferencing application that is shared among many distributed participants), data feeds (e.g., stock quotes), and interactive gaming (e.g., distributed interactive virtual environments or multiplayer games such as Quake). For each of these applications, an extremely useful abstraction is the notion of a multicast: the sending of a packet from one sender to multiple receivers with a single “transmit” operation.
In this section we consider the network layer aspects of multicast. We continue our primary focus on the Internet here, as multicast is much more mature (although it is still undergoing significant develop and evolution) in the Internet than in ATM networks. We will see that as in the unicast case, routing algorithms again play a central role in the network layer. We will also see, however, that unlike the unicast case, Internet multicast is not a connectionless service –state information for a multicast connection must be established and maintained in routers that handle multicast packets sent among hosts in a so-called multicast group. This, in turn, will require a combination of signaling and routing protocols in order to set up, maintain, and tear down connection state in the routers.
Introduction: The Internet multicast abstraction and multicast groups
From a networking standpoint, the multicast abstraction — a single send operation that results in copies of the sent data being delivered to many receivers – can be implemented in many ways. One possibility is for the sender to use a separate unicast transport connection to each of the receivers. An application-level data unit that is passed to the transport layer is then duplicated at the sender and transmitted over each of the individual connections. This approach implements a one-sender-to-many-receivers multicast abstraction using an underlying unicast network layer [Talpade 1997]. It requires no explicit multicast support from the network layer to implement the multicast abstraction; multicast is emulated using multiple point-to-point unicast connections. This is shown in the left of Figure 4.8-1, with network routers shaded in white to indicate that they are not actively involved in supporting the multicast. Here, the multicast sender uses three separate unicast connections to reach the three receivers.
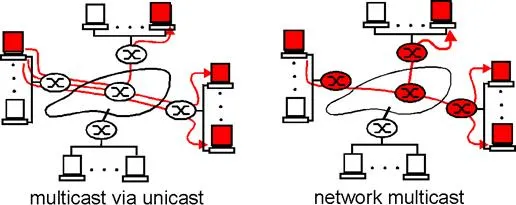
Figure 4.8-1: two approaches towards implementing the multicast abstraction
A second alternative is to provide explicit multicast support at the network layer. In this latter approach, a single datagram is transmitted from the sending host. This datagram (or a copy of this datagram) is then replicated at a network router whenever it must be forwarded on multiple outgoing links in order to reach the receivers. The right side of Figure 4.8-1 illustrates this second approach, with certain routers shaded in red to indicate that they are actively involved in supporting the multicast. Here, a single datagram is transmitted by the sender. That datagram is then duplicated by the router within the network; one copy is forwarded to the uppermost receiver and another copy is forwarded towards the rightmost receivers. At the rightmost router, the multicast datagram is broadcast over the Ethernet that connects the two receivers to the rightmost router. Clearly, this second approach towards multicast makes more efficient use of network bandwidth in that only a single copy of a datagram will ever traverse a link. Other the other hand, considerable network layer support is needed to implement a mutlicast-aware network layer. For the remainder of this section we will focus on a multicast-aware network layer, as this approach is implemented in the Internet and poses a number of interesting challenges.
With multicast communication, we are immediately faced with two problems that are much more complicated than in the case of unicast – how to identify the receivers of a multicast datagram and how to address a datagram sent to these receivers.
In the case of unicast communication, the IP address of the receiver (destination) is carried in each IP unicast datagram and identifies the single recipient. But in the case of multicast, we now have multiple receivers. Does it make sense for each multicast datagram to carry the IP addresses of all of the multiple recipients? While this approach might be workable with a small number of recipients, it would not scale well to the case of hundreds or thousands of receivers; the amount of addressing information in the datagram would swamp the amount of data actually carried in the datagram’s payload field. Explicit identification of the receivers by the sender also requires that the sender know the identities and addresses of all of the receivers. We will see shortly that there are cases where this requirement might be undesirable.
For these reasons, in the Internet architecture (and the ATM architecture as well), a multicast datagram is addressed using address indirection. That is, a single “identifier” is used for the group of receivers, and a copy of the datagram that is addressed to the group using this single “identifier” is delivered to all of the multicast receivers associated with that group. In the Internet, the single “identifier” that represents a group of receivers is a Class D multicast address, as we saw earlier in section 4.4. The group of receivers associated with a class D address is referred to as a multicast group. The multicast group abstraction is illustrated in Figure 4.8-2. Here, four hosts (shown in red) are associated with the multicast group address of 226.17.30.197 and will receive all datagrams addressed to that multicast address. The difficulty that we must still address is the fact that each host has a unique IP unicast address that is completely independent of the address of the multicast group in which it is participating.
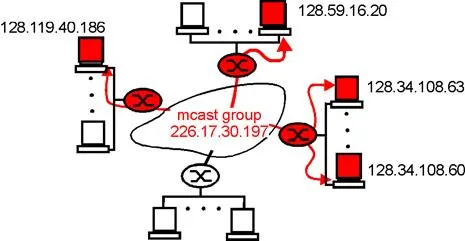
Figure 4.8-2: the multicast group: a datagram addressed to the group
is delivered to all members of the multicast group
While the multicast group abstraction is simple, it raises a host (pun intended) of questions. How does a group get started and how does it terminate? How is the group address chosen? How are new hosts added to the group (either as senders or receivers)? Can anyone join a group (and send to, or receive from, that group) or is group membership restricted and if so, by whom? Do group members know the identities of the other group members as part of the network layer protocol? How do the network routers interoperate with each other to deliver a multicast datagram to all group members? For the Internet, the answers to all of these questions involve the Internet Group Management Protocol [RFC 2236]. So, let us next consider the IGMP protocol and then return to these broader questions.
The IGMP Protocol
The Internet Group Management protocol, IGMP version 2 [RFC 2236], operates between a host and its directly attached router (informally, think of the directly-attached router as the “first-hop” router that a host would see on a path to any other host outside its own local network, or the “last-hop” router on any path to that host), as shown in Figure 4.8-3. Figure 4.8-3 shows three first-hop multicast routers, each connected to its attached hosts via one outgoing local interface. This local interface is attached to a LAN in this example, and while each LAN has multiple attached hosts, at most a few of these hosts will typically belong to a given multicast group at any given time.
IGMP provides the means for a host to inform its attached router that an application running on the host wants to join a specific multicast group. Given that the scope of IGMP interaction is limited to a host and its attached router, another protocol is clearly required to coordinate the multicast routers (including the attached routers) throughout the Internet, so that multicast datagrams are routed to their final destinations. This latter functionality is accomplished by the network layer multicast routing algorithms such as PIM, DVMRP, MOSFP and BGP. We will study multicast routing algorithms in sections 4.8.3 and 4.8.4. Network layer multicast in the Internet thus consists of two complementary components: IGMP and multicast routing protocols.
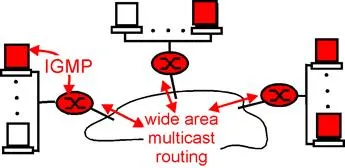
Figure 4.8-3: the two components of network layer multicast: IGMP
and multicast routing protocols
Although IGMP is referred to as a “group membership protocol,” the term is a bit misleading since IGMP operates locally, between a host and an attached router. Despite its name, IGMP is not a protocol that operates among all the hosts that have joined a multicast group, hosts that may be spread around the world. Indeed, there is no network-layer multicast group membership protocols that operates among all the Internet hosts in a group. There is no protocol, for example, that allows a host to determine the identities of all of the other hosts, network-wide, that have joined the multicast group. (See the homework problems for a further exploration of the consequences of this design choice).
| IGMP Message types | Sent by | Purpose |
| membership query: general | router | query multicast groups joined by attached hosts |
| membership query: specific | router | query if specific multicast group joined by attached hosts |
| membership report | host | report host wants to join or is joined to given multicast group |
| leave group | host | report leaving given multicast group |
Table 4.8-1: IGMP v2 Message types
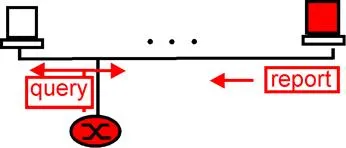
Figure 4.8-4: IGMP member query and membership report
IGMP version 2 [Fenner 1997] has only three message types, as shown in Table 4.8-1. A general membership_query messageis sent by a router to all hosts on an attached interface (e.g., to all hosts on a local area network) to determine the set of all multicast groups that have been joined by the hosts on that interface. A router can also determine if a specific multicast group has been joined by hosts on an attached interface using a specific membership_query. The specific query includes the multicast address of the group being queried in the multicast group address field of the IGMP membership_query message, as shown in Figure 4.8-5.
Hosts respond to a membership_query message with an IGMP membership_report message, as illustrated in Figure 4.8-4. Membership_report messages can also be generated by a host when an application first joins a multicast group without waiting for a membership_query message from the router . Membership_report messages are received by the router, as well as all hosts on the attached interface (e.g., in the case of a LAN). Each membership_report contains the multicast address of a single group that the responding host has joined. Note that an attached router doesn’t really care which hosts have joined a given multicast group or even how many hosts on the same LAN have joined the same group. (In either case, the router’s work is the same – it must run a multicast routing protocol together with other routers to ensure that it receives the multicast datagrams for the appropriate multicast groups.) Since a router really only cares about whether one or more of its attached hosts belong to a given multicast group, it would ideally like to hear from only one of the attached hosts that belongs to each group (why waste the effort to receive identical responses from multiple hosts?). IGMP thus provides an explicit mechanism aimed at decreasing the number of membership_report messages generated when multiple attached hosts belong to the same multicast group.
Specifically, each membership_query message sent by a router also includes a “maximum response time” value field, as shown in Figure 4.8-5. After receiving a membership_query message and before sending a membership_report message for a given multicast group, a host waits a random amount of time between zero and the maximum response time value. If the host observes a membership_report message from some other attached host for that given multicast group, it suppresses (discards) its own pending membership_report message, since the host now knows that the attached router already knows that one or more hosts are joined to that multicast group. This form of feedback suppression is thus a performance optimization — it avoids the transmission of unnecessary membership_report messages. Similar feedback suppression mechanisms have been used in a number of Internet protocols, including reliable multicast transport protocols [Floyd 1997].
The final type of IGMP message is the leave_group message. Interestingly, this message is optional! But if it is optional, how does a router detect that there are no longer any hosts on an attached interface that are joined to a given multicast group? The answer to this question lies in the use of the IGMP membership_query message. The router infers that no hosts are joined to a given multicast group when no host responds to a membership_query message with the given group address. This is an example of what is sometimes called soft state in an Internet protocol. In a soft state protocol, the state (in this case of IGMP, the fact that there are hosts joined to a given multicast group) is removed via a timeout event (in this case, via a periodic membership_query message from the router) if it is not explicitly refreshed (in this case, by a membership_report message from an attached host). It has been argued that soft-state protocols result in simpler control than hard-state protocols, which not only require state to be explicitly added and removed, but also require mechanisms to recover from situation where the entity responsible for removing state has terminated prematurely or failed [Sharma 1997]. An excellent discussion of soft state can be found in [Raman 1999].
The IGMP message format is summarized in Figure 4.8-5. Like ICMP, IGMP messages are carried (encapsulated) within an IP datagram, with an IP protocol number of 2.

Figure 4.8-5: IGMP message format
Having examined the protocol for joining and leaving multicast groups we are now in a better position to reflect on the current Internet multicast service model, which is based on the work of Steve Deering [RFC 1112, Deering 1991]. In this multicast service model, any host can “join” a multicast group at the network layer. A host simply issues a membership_report IGMP message to its attached router. That router, working in concert with other Internet routers, will soon begin delivering multicast datagrams to the host. Joining a multicast group is thus receiver-driven. A sender need not be concerned with explicitly adding receivers to the multicast group (as is the case with multicast in ATM) but neither can it control who joins the group and therefore receives datagrams sent to that group. Indeed, recall that it is not possible at the network layer to even know which hosts, network-wide, have joined a multicast group. Similarly, there is no control over who sends to the multicast group. Datagrams sent by different hosts can be arbitrarily interleaved at the various receivers (with different interleaving possible at different receivers). A malicious sender can inject datagrams into the multicast group datagram flow. Even with benign senders, since there is no network layer coordination of the use of multicast addresses, it is possible that two different multicast groups will choose to use the same multicast address. From a multicast application viewpoint, this will result in interleaved extraneous multicast traffic.
These problems may seem to be insurmountable drawbacks for developing multicast applications. All is not lost, however. Although the network layer does not provide for filtering, ordering, or privacy of multicast datagrams, these mechanisms can all be implemented at the application layer. There is also on-going work aimed at adding some of this functionality into the network layer [Cain 1999]. In many ways, the current Internet multicast service model reflects the same philosophy as the Internet unicast service model — an extremely simple network layer with additional functionality being provided in the upper layer protocols in the hosts of the “edges” of the network. This philosophy has been unquestionably successful for the unicast case; whether the minimalist network layer philosophy will be equally successful for the multicast service model still remains an open question. An interesting discussion of an alternate multicast service model is [Holbrook 1999].
Multicast Routing: the general case
In the previous section we have seen how the IGMP protocol operates at the “edge” of the network between a router and its attached hosts, allowing a router to determine what multicast group traffic it needs to receive for forwarding to its attached hosts. We can now focus our attention on just the multicast routers: how should they route packets amongst themselves in order to insure that each router receives the multicast group traffic that it needs.
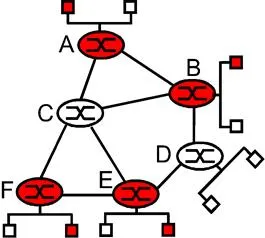
Figure 4.8-6: Multicast hosts, their attached routers, and other routers
Figure 4.8-6 illustrates the setting for the multicast routing problem. Let us consider a single multicast group and assume that any router that has an attached host that has joined this group may either send or receive traffic addressed this group [footnote 1]. In Figure 4.8-6, hosts joined to the multicast group are represented by shaded red squares; their immediately attached router is also shaded in red. As shown in Figure 4.8-6, among the population of multicast routers, only a subset of these routers (those with attached hosts that are joined to the multicast group) actually need to receive the multicast traffic. In Figure 4.8-6 only routers A, B, E and F need to receive the multicast traffic. Since none of the attached hosts to router D are joined to the multicast group and since router C has no attached hosts, neither C nor D need to receive the multicast group traffic.
The goal of multicast routing then is to find a tree of links that connects all of the routers that have attached hosts belonging to the multicast group. Multicast packets will then be routed along this tree from the sender to all of the hosts belonging to the multicast tree. Of course, the tree may contain routers that do not have attached hosts belonging to the multicast group (e.g., in Figure 4.8-6, it is impossible to connect routers A, B, E, and F in a tree without involving either routers C and/or D).
In practice, two approaches have been adopted for determining the multicast routing tree. The two approaches differ according to whether a single tree is used to distribute the traffic for all senders in the group, or whether a source-specific routing tree is constructed for each individual sender:
- Group-shared tree. In the group-shared tree approach, only a single routing tree is constructed for the entire multicast group. For example, the single multicast tree shown in red in the left of Figure 4.8-7, connects routers A, B, C, E, and F. (Following our conventions from Figure 4.8-6, router C is not shaded in red. Although it participates in the multicast tree, it has no attached hosts that are members of the multicast group). Multicast packets will flow only over those links shown in red. Note that the links are bi-directional, since packets can flow in either direction on a link.
- Source-based trees. In a source-based approach, an individual routing tree is constructed for each sender in the multicast group. In a multicast group with N hosts, N different routing trees will be constructed for that single multicast group. Packets will be routed to multicast group members in a source-specific manner. In the right of Figure 4.8-7, two source-specific multicast trees are shown, one rooted at A and another rooted at B. Note that not only are there different links than in the group-shared tree case, (e.g., the link from BC is used in the source-specific tree routed at B, but not in the group-shared tree in the left of Figure 4.8-7), but that some links may also be used only in a single direction.
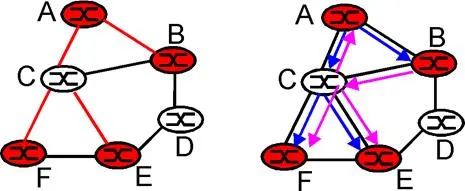
Figure 4.8-7: A single, shared tree (left), and two source-based trees (right)
Multicast Routing using a Group-Shared Tree
Let us first consider the case where all packets sent to a multicast group are to be routed along the same singe multicast tree, regardless of the sender. In this case, the multicast routing problem appears quite simple: find a tree within the network that connects all routers having an attached host belonging to that multicast group. In Figure 4.8-7 (left), the tree composed of red links is one such tree. Note that the tree contains routers that have attached hosts belonging to the multicast group (i.e., routers A, B, E and F) as well as routers that have no attached hosts belonging to the multicast group. Ideally, one might also want the tree to have minimal “cost.” If we assign a “cost” to each link (as we did for unicast routing in section 4.2.2) then an optimal multicast routing tree is one having the smallest sum of the tree link costs. For the link costs given in Figure 4.8-8, the optimum multicast tree (with a cost of 7) is shown in red.
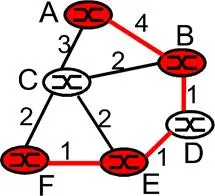
Figure 4.8-8: A minimum cost multicast tree
The problem of finding a minimum cost tree is known as the Steiner Tree problem [Hakimi 1971]. Solving this problem has been shown to be NP-complete [Garey 1978], but the approximation algorithm in [Kou 1981] has been proven to be within a constant of the optimal solution. Other studies have shown that, in general, approximation algorithms for the Steiner tree problem do quite well in practice [Wall 1982, Waxman 1988, Wei 1993].
Even though good heuristics exist for the Steiner tree problem, it is interesting to note that none of the existing Internet multicast routing algorithms have been based on this approach. Why? One reason is that information is needed about all links in the network. Another reason is that in order for a minimum cost tree to be maintained, the algorithm needs to be re-run whenever link costs change. Finally, we will see that other considerations, such as the ability to leverage the routing tables that have already been computed for unicast routing, play an important role in judging the suitability of a multicast routing algorithm. In the end, performance (and optimality) are but one of many concerns.
An alternate approach towards determining the group-shared multicast tree, one that is used in practice by several Internet multicast routing algorithms, is based on the notion of defining a center node (also known as a rendezvous point or a core) in the single shared multicast routing tree. In the center-based approach, a center node is first identified for the multicast group. Routers with attached hosts belonging to the multicast group then unicast so-called “join” messages addressed to the center node. A join message is forwarded using unicast routing towards the center until it either arrives at a router that already belongs to the multicast tree or arrives at the center. In either case, the path that the join message has followed defines the branch of the routing tree between the edge router that initiated the join message and the center. One can think of this new path as being “grafted” onto the existing multicast tree for the group.
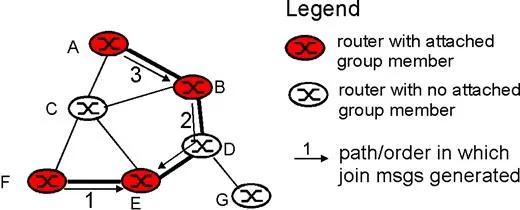
Figure 4.8-9: Constructing a center-based tree
Figure 4.8-9 illustrates the construction of a center-based multicast routing tree. Suppose that router E is selected as the center of the tree. Node F first joins the multicast group and forwards a join message to E. The single link EF becomes the initial multicast tree. Node B then joins the multicast tree by sending its join message to E. Suppose that the unicast path route to E from B is via D. In this case, the join message results in the path BDE being grafted onto the multicast tree. Finally, node A joins the multicast group by forwarding its join message towards E. Let us assume that A’s unicast path to E is through B. Since B has already joined the multicast tree, the arrival of A’s join message at B will result in the AB link being immediately grafted on to the multicast tree.
A critical question for center-based tree multicast routing is the process used to select the center. Center selection algorithms are discussed in [Wall 1982, Thaler97, Estrin97]. [Wall 982] shows that centers can be chosen so that the resulting tree is within a constant factor of optimum (the solution to the Steiner tree problem).
Multicast Routing using a Source-Based Tree
While the multicast routing algorithms we have studied above construct a single, shared routing tree that is used to route packets from all senders, the second broad class of multicast routing algorithms construct a multicast routing tree for each source in the multicast group.
We have already studied an algorithm (Dijkstra’s link-state routing algorithm, in section 4.2.1) that computes the unicast paths that are individually the least cost paths from the source to all destinations. The union of these paths might be thought of as forming a least unicast-cost path tree (or a shortest unicast path tree, if all link costs are identical). Figure 4.8-10 shows the construction of the least cost path tree rooted at A. By comparing the tree in Figure 4.8-10 with that of Figure 4.8-8, it is evident that the least cost path tree is not the same as the minimum overall cost tree computed as the solution to the Steiner tree problem. The reason for this difference is that the goals of these two algortihms are different: least unicast-cost path tree minimizes the cost from the source to each of the destinations (that is, there is no other tree that has a shorter distance path from the source to any of the destinations), while the Steiner tree minimizes the sum of the link costs in the tree. You might also want to convince yourself that the least unicast-cost path tree often differs from one source to another (e.g., the source tree rooted at A is different from the source tree rooted at E in Figure 4.8-10).
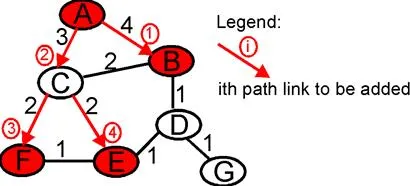
Figure 4.8-10: Construction of a least cost path routing tree
The least cost path multicast routing algorithm is a link-state algorithm. It requires that each router know the state of each link in the network in order to be able to compute the least cost path tree from the source to all destinations. A simpler multicast routing algorithm, one which requires much less link state information than the least cost path routing algorithm, is the reverse path forwarding (RPF) algorithm.
The idea behind reverse path forwarding is simple, yet elegant. When a router receives a multicast packet with a given source address, it transmits the packet on all of its outgoing links (except the one on which it was received) only if the packet arrived on the link that is on its own shortest path back to the sender. Otherwise the router simply discards the incoming packet without forwarding it on any of its outgoing links. Such a packet can be dropped because the router knows it either will receive, or has already received, a copy of this packet on the link that is on its own shortest path back to the sender. (You might want to convince yourself that this will, in fact, happen). Note that reverse path forwarding does not require that a router know the complete shortest path from itself to the source; it need only know the next hop on its unicast shortest path to the sender.
Figure 4.8-11 illustrates RPF. Suppose that the links in red represent the least cost paths from the receivers to the source (A). Router A initially multicasts a source-S packet to routers C and B. Router B will forward the source-S packet it has received from A (since A is on its least cost path to A) to both C and D. B will ignore (drop, without forwarding) any source-S packets it receives from any other routers (e.g., from routers C or D).
Let us now consider router C, which will receive a source-S packet directly from A as well as from B. Since B is not on C’s own shortest path back to A, C will ignore (drop) any source-S packets it receives from B. On the other hand, when C receives an source-S packet directly from A it will forward the packet to routers B, E, and F.
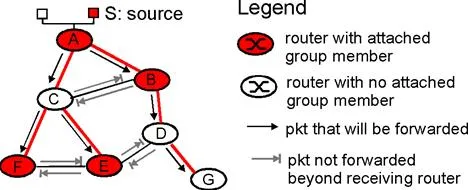
Figure 4.8-11: Reverse Path Forwarding
RPF is a nifty idea. But considers what happens at router D in Figure 4.8-11. It will forward packets to router G, even though router G has no attached hosts that are joined to the multicast group. While this is not so bad for this case where D has only a single downstream receiver, G, imagine what would happen if there were thousands of routers downstream from D! Each of these thousands of routers would receive unwanted multicast packets. (This scenario is not as far-fetched as it might seem. The initial MBone [Casner 1992, Macedonia 1994], the first global multicast network suffered from precisely from this problem at first!)
The solution to the problem of receiving unwanted multicast packets under RPF is known as pruning. A multicast router that receives multicast packets and has no attached hosts joined to that group will send a prune message to its upstream router. If a router receives prune messages from each of its downstream routers, then it can forward a prune message upstream. Pruning is illustrated in Figure 4-8.12.
While pruning is conceptually straightforward, two subtle issues arise. First, pruning requires that a router know which routers downstream are dependent on it for receiving their multicast packets.. This requires additional information beyond that required for RPF alone. A second complication is more fundamental: if a router sends a prune message upstream, then what should happen if a router later needs to join that multicast group? Recall that under RPF, multicast packets are “pushed” down the RPF tree to all routers. If a prune message removes a branch from that tree, then some mechanism is needed to restore that branch. One possibility is to add a graft message that allows a router to “unprune” a branch. Another option is to allow pruned branches to time-out and be added again to the multicast RPF tree; a router can then re-prune the added brach if the multicast traffic is still not wanted.
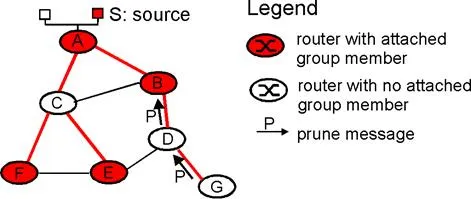
Figure 4.8-12: Pruning a RPF tree.
Multicast Routing in the Internet
Having now studied multicast routing algorithms in the abstract, let’s now consider how these algorithms are put into practice in today’s Internet by examining the three currently-standardized Internet multicast routing protocls: DVMRP, MOSPF, and PIM.
DVMRP
The first multicast routing protocol used in the Internet and the most widely supported multicast routing algorithm [IP Multicast Initiative 1998] is the distance vector multicast routing protocol (DVMRP) [RFC1075]. DVMRP implements source-based trees with reverse path forwarding, pruning, and grafting. DVMRP uses a distance vector algorithm (see section 4.2) that allows each router to compute the outgoing link (next hop) that is on its shortest path back to each possible source. This information is then used in the RPF algorithm, as discussed above. A public copy of DVMRP software is available at [mrouted 1996].
In addition to computing next hop information, DVMRP also computes a list of dependent downstream routers for pruning purposes. When a router has received a prune message from all of its dependent downstream routers for a given group, it will propagate a prune message upstream to the router from which it receives its multicast traffic for that group. A DVMRP prune message contains a prune lifetime (with a default value of two hours) that indicates how long a pruned branch will remain pruned before being automatically restored. DVMRP graft messages are sent by a router to its upstream neighbor to force a previously-pruned branch to be added back on to the multicast tree.
Before examining other multicast routing algorithms, let us consider how multicast routing can be deployed in the Internet. The crux of the problem is that only a small fraction of the Internet routers are multicast capable. If one router is multicast capable but all of its immediate neighbors are not, is this lone island of multicast routing lost in a sea of unicast routers? Most decidedly not! Tunneling, a technique we examined earlier in the context of IP version 6 (section 4.7), can be used to create a virtual network of multicast capabale routers on top of a physical network that contains a mix of unicast and multicast routers. This is the approach taken in the Internet MBone.
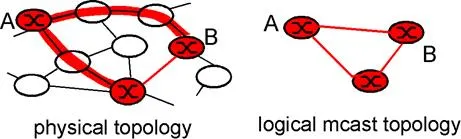
Figure 4.8-13: Multicast tunnels
Multicast tunnels are illustrated in Figure 4.8-13. Suppose that multicast router A wants to forward a multicast datagram to multicast router B. Suppose that A and B are not physical connected to each other and that the intervening routers between A and B are not multicast capable. To implement tunneling, router A takes the multicast datagram and “encapsulates” it [RFC 2003]t inside a standard unicast datagram. That is, the entire multicast datagram (including source and multicast address fields) is carried as the payload of an IP unicast datagram – a complete multicast IP dagram inside of a unicast IP datagram! The unicast datagram is then addressed to the unicast address of router B and forwarded towards B by router A. The unicast routers between A and B dutifully forward the unicast packet to B, blissfully unaware that the unicast datagram itself contains a multicast datagram. When the unicast datagram arrives at B, B then extracts the multicast datagram. B may then forward the multicast datagram on to one of its attached hosts, forward the packet to a directly attached neighboring router that is multicast capable, or forward the multicast datagram to another logical multicast neighbor via another tunnel.